임베딩
임베딩은 희소 벡터 데이터를 밀집 벡터 데이터로 변환하는 것을 의미합니다.
희소 벡터 데이터는 원-핫 인코딩된 데이터입니다. 원-핫 인코딩은 각 데이터에 인덱스를 할당하고 데이터의 고유한 수만큼 차원을 가진 벡터의 해당 인덱스에 1을 입력합니다.
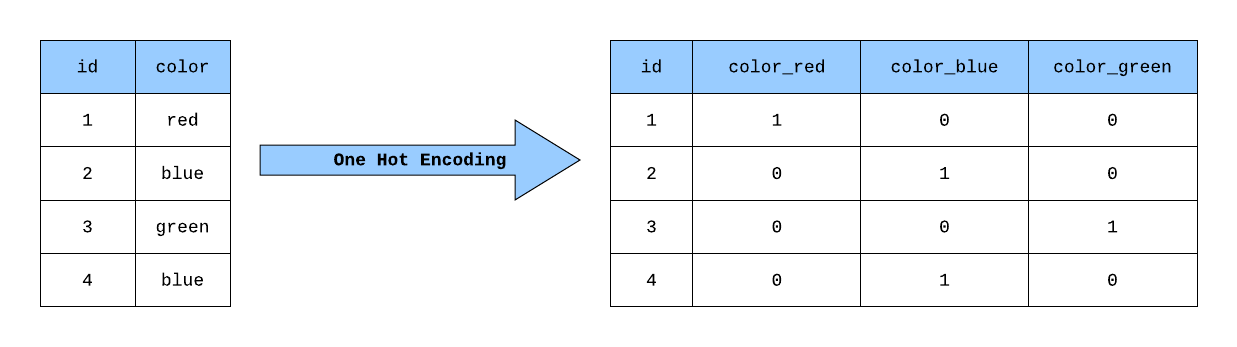
위의 그림에서 빨간색은 (1,0,0), 파란색은 (0,1,0), 녹색은 (0,0,1)로 표현할 수 있습니다.
희소 벡터 데이터와 달리 밀집 벡터 데이터는 대부분 0인 데이터를 나타냅니다.

희소 벡터 데이터에서 밀집 벡터 데이터로 변환할 때 가중치 테이블을 사용하여 변환하며, 이 가중치 테이블은 역전파를 통해 지속적으로 업데이트됩니다.
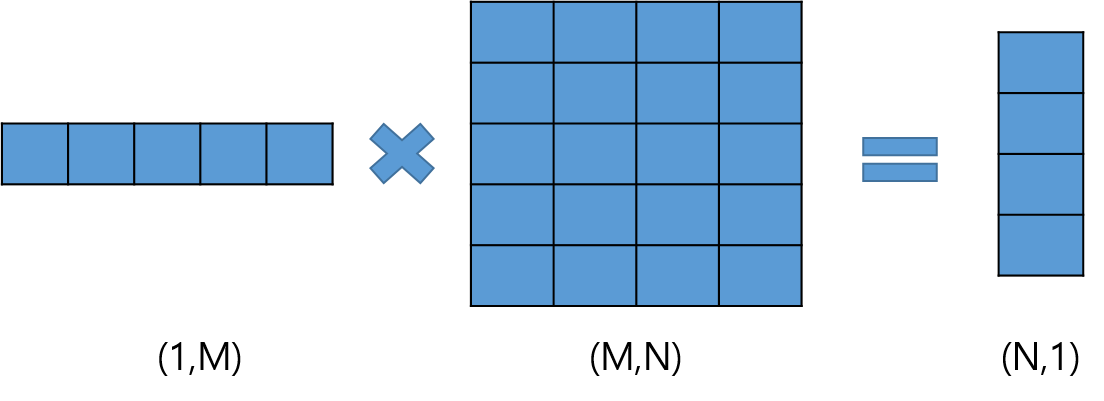
내장 프로세스는 다음과 같이 요약할 수 있습니다.
- 원-핫 인코딩으로 벡터 생성
- 임베딩은 1단계에서 생성한 벡터에 가중치 테이블을 곱하여 생성됩니다.
워드 임베딩
먼저 포함하려면 원-핫 인코딩 벡터가 필요합니다. 즉, 단어는 원-핫 인코딩에 의해 희소 벡터로 변환되어야 하는데, 원-핫 인코딩은 주어진 문서에 나타나는 단어의 사전을 구축하여 수행됩니다.
이러한 방식으로 희소 벡터를 생성할 수 있고 이를 임베딩하여 조밀한 벡터를 생성할 수 있습니다.
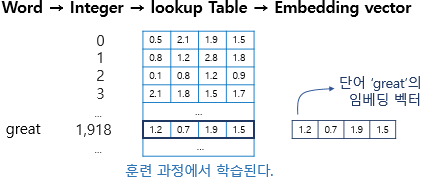
위의 이미지는 great라는 단어를 삽입하는 과정을 보여줍니다.
이것은 조회 테이블이라는 가중치 테이블을 통해 임베딩 벡터를 가져오는 과정이며 “훌륭함”으로 인덱싱됩니다.
프레임워크의 임베딩 레이어에서는 원-핫 코딩은 하지 않고 사전의 크기 즉, 입력 차원을 입력하고
단어의 색인은 다음과 같은 처리를 허용합니다. B. 원-핫 인코딩.